Neural Net Gradient Optimization
Spark's implementation of artificial neural nets is a little sparse. For instance, the only activation function is the private SigmoidFunction. It seems like there are other ways of training large ANNs at scale. This is an interesting article where data scientists used Deep Java Library (DJL - not to be confused with DL4J) in a Spark framework to orchestrate PyTorch model training.
In theory, one could add one's own activation functions and extract the weights that Spark generated. I took a look at the code of MultiLayerPerceptronClassifier and saw how in each epoch, it broadcasts the weights to all the executors and then uses RDD.treeAggregate to compute the gradient per vector, per partition and then combine them all. In the case of BFGS numerical optimization technique, the Breeze library is used and the call to treeAggregate was invoked as a callback to its BFGS implementation. Note that this was done on Spark's driver and the the loss and averaged gradient are calculated there.
Here, "we cannot write down the actual mathematical formula for the function we’re optimizing. (The technical term for the function that is being optimized is response surface.)" [1]
The format of the broadcast weights confused me at first as they're a one dimensional vector when I was expecting matrices (see Neural Nets are just Matrices). On closer inspection I saw that this vector contained all the values in all the matrices for all the layers and was sliced and diced accordingly.
Hyperparameter Optimization via Randomisation
One level up, a meta-optimization if you like, we want to tune the parameters for the neural nets (choice of activation function, size and cardinality of layers etc). Spark only offers ParamGridBuilder out of the box. This is really just a simple class that creates a Cartesian product of possible parameters. This is fed to CrossValidator.setEstimatorParamMaps as a simple Array so the cross validator can explore a parameter space by brute force.
There is a more clever way that involves a random search. "for any distribution over a sample space with a finite maximum, the maximum of 60 random observations lies within the top 5% of the true maximum, with 95% probability" [1]
It seems odd but it's true. Let's look at the probability of not being in the top 5%. And let's call this top 5% space, X. Then:
P(x ∈ X) = 0.05
so, the probability of a random point not being in the top 5% is:
P(¬x ∈ X) = 1 - 0.05
Now, given N points, the probability of them all not being in the top 5% is:
P(¬xi ∈ X ∀i) = (1 - 0.05)N
So, the probability being in the top 5% is one minus this.
Say, we want 95% probability we're in the top 5%, solve this equation and you'll see N is slightly less than 60. QED.
Exploration of Space
The state space of parameters can be explored for maxima or minima via various techniques. There are more intelligent ways of doing it but one may is using Monte Carlo techniques. Here in my GitHub account is a Python/Theano/PyMC3 example using Metropolis-Hastings to sample from a beautifully named Himmelblau function. This function is nice as we know analytically that it happens to have four local minima. But let's pretend we don't know that:
 |
| The Himmelblau function (top) and finding its minima (bottom) |
The path to explore the space starts in a random place but quickly finds one of the local minima.
 |
| Finding two (equal) local minima. |
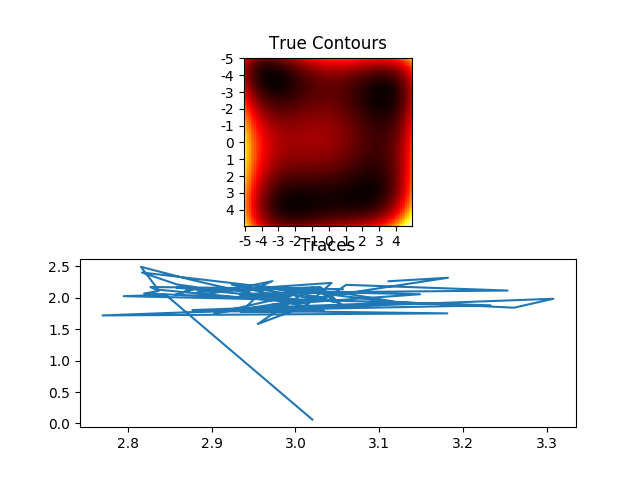 |
| Local minima (3.0, 2.0) found in 60 steps |
[1] Alice Zheng on O'Reilly

No comments:
Post a Comment