K-Means is a clustering algorithm that tells you were the centres are in a set of data points. It "has the major disadvantage that you must pick k [the number of centres] in advance. On the plus side, it’s easy to implement". A simple implementation is just a few lines of Scala although it can be used on a much larger scale in MLLib/Spark.
First, let's create some data - just rows of x,y such that when plotted in R it looks like this:
data <- read.csv("/tmp/point.csv", header=F)
matplot(data[,1],data[,2] ,type="p", pch=3, xlab="x", ylab="y")
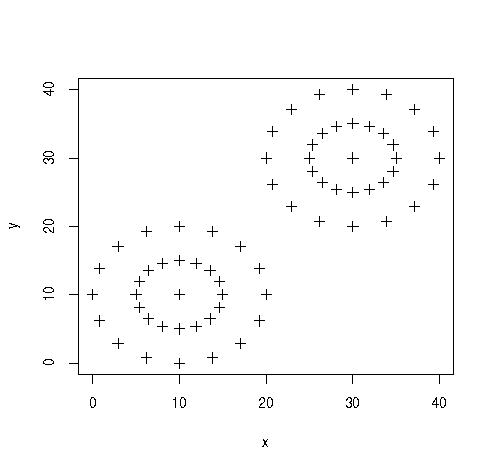
It's clear where to the human eye that there are 2 clusters here and where their centres are, although it would be much harder just given the raw data.
The snippet of Scala code to calculate K-Means looks something like this:
.
.
case class Distance(point: Point2D, distance: Double)
case class Point2D(x: Double, y: Double)
.
.
implicit val pointOrdering = new Ordering[Distance] {
override def compare(x: Distance, y: Distance): Int = (x.distance - y.distance).toInt
}
def iterate(centres: Seq[Point2D], others: Seq[Point2D]): Seq[Point2D] = {
val clusterPairs = centres.map(centre => (centre, Seq[Point2D]()))
val clusters = Map(clusterPairs: _*)
val assigned = assign(others, centres, clusters)
assigned.map(centrePoint => update(centrePoint._2 :+ centrePoint._1)).toSeq.to[collection.immutable.Seq]
}
def update(points: Seq[Point2D]): Point2D = {
val distances = points.map(point => sumOfDistances(point, points))
distances.min.point
}
def sumOfDistances(point: Point2D, others: Seq[Point2D]): Distance = {
val distances = others.map(other => distanceFn(other, point))
Distance(point, distances.sum)
}
def distancesFrom(centre: Point2D, others: Seq[Point2D]): Seq[Distance] =
others.map(point => Distance(point, distanceFn(centre, point)))
Where we call iterate an arbitrary number of times until we're happy we have the centres. The iterate method is initially called with k randomly chosen points that will act as our initial guesses at where the centres are. With each iteration, out guess will be refined.
For each iteration, we do two things. First we assign each point to one of our k estimated centres. Then, within each grouping, we find the point that is the most central. These points will be the basis for our next iteration.
We define the central points within a grouping as those that have the minimum value of adding up all the distances to the other points.
The interesting thing is that the resulting cluster points may change somewhat between runs as the initial choice of points may make a difference. (that is, it's unstable) Therefore, it might be necessary to run it a few times and see the most common outcome.
We can verify the results in R with:
> kmeans(data, 2) # 2 being the number of clusters we're expecting
K-means clustering with 2 clusters of sizes 33, 33
Cluster means:
V1 V2
1 30 30
2 10 10
Which is the same result as my code when run with 10 iterations and taking the most popular results from 10 runs.

No comments:
Post a Comment