Recursion can be more expensive than iterating over the same code.
Take this iterative method:
int iterativeCall(int count, int maxCalls) {
for (int i = 0 ; i < maxCalls ; i++) {
count ^= count +1;
}
return count;
}
And this recursive method:
int recursiveCall(int count, int countDown) {
if (countDown <= 0)
return count;
count ^= count +1;
return recursiveCall(count, countDown - 1);
}
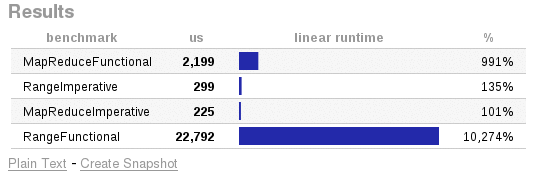
And compare the two. Using Caliper, the difference looks something like this:

To make recursive loops perform more like iterative loops, various tricks can be employed to make the compiled code loop over a block rather than jump recursively.
I noticed Hotspot do something similar to this. It's not fully optimized because it appears to reduce rather than avoid recursions.
This is how I did it. If we now add a static main method to our class containing the code above:
public static void main(String[] args) {
RecursionVsIterativeBenchmark app = new RecursionVsIterativeBenchmark();
for (int i = 0 ; i < 1000 ; i++) {
app.recursiveCall(0, 1000);
}
}
and run the code with:
/usr/java/jdk1.7.0.fastdebug/bin/java -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=print,com.henryp.test.recursion.RecursionVsIterativeBenchmark -server -XX:+PrintAssembly -XX:CompileThreshold=90000 -cp /home/henryp/workspace/myPerformance/target/classes/:/home/henryp/.m2/repository/com/google/caliper/caliper/0.5-rc1/caliper-0.5-rc1.jar:/home/henryp/.m2/repository/com/google/code/findbugs/jsr305/1.3.9/jsr305-1.3.9.jar:/home/henryp/.m2/repository/com/google/code/gson/gson/1.7.1/gson-1.7.1.jar:/home/henryp/.m2/repository/com/google/guava/guava/11.0.1/guava-11.0.1.jar:/home/henryp/.m2/repository/com/google/code/java-allocation-instrumenter/java-allocation-instrumenter/2.0/java-allocation-instrumenter-2.0.jar:/home/henryp/.m2/repository/asm/asm/3.3.1/asm-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-analysis/3.3.1/asm-analysis-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-commons/3.3.1/asm-commons-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-tree/3.3.1/asm-tree-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-util/3.3.1/asm-util-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-xml/3.3.1/asm-xml-3.3.1.jar com.henryp.test.recursion.RecursionVsIterativeBenchmark
to make hotspot spit out the assembly code, we see:
{method}
- klass: {other class}
- this oop: 0x000000040d0e7970
- method holder: 'com/henryp/test/recursion/RecursionVsIterativeBenchmark'
- constants: 0x000000040d0e7078 constant pool [42] for 'com/henryp/test/recursion/RecursionVsIterativeBenchmark' cache=0x000000040d1372c0
- access: 0x81000000
- name: 'recursiveCall'
- signature: '(II)I'
- max stack: 4
- max locals: 3
- size of params: 3
- method size: 17
- vtable index: 21
- i2i entry: 0x00007f8d0501d960
- adapter: 0x00007f8d080b8f20
- compiled entry 0x00007f8d050dc877
- code size: 21
- code start: 0x000000040d0e7928
- code end (excl): 0x000000040d0e793d
- method data: 0x000000040d193b08
- checked ex length: 0
- linenumber start: 0x000000040d0e793d
- localvar length: 3
- localvar start: 0x000000040d0e794a
#
# int ( com/henryp/test/recursion/RecursionVsIterativeBenchmark:NotNull *, int, int )
#
#r018 rsi:rsi : parm 0: com/henryp/test/recursion/RecursionVsIterativeBenchmark:NotNull *
#r016 rdx : parm 1: int
#r010 rcx : parm 2: int
# -- Old rsp -- Framesize: 32 --
#r089 rsp+28: pad2, in_preserve
#r088 rsp+24: pad2, in_preserve
#r087 rsp+20: pad2, in_preserve
#r086 rsp+16: pad2, in_preserve
#r085 rsp+12: pad2, in_preserve
#r084 rsp+ 8: return address
#r083 rsp+ 4: Fixed slot 1
#r082 rsp+ 0: Fixed slot 0
#
000 N94: # B1 <- 1="" block="" font="" freq:="" head="" is="" junk="" nbsp="">
000 movl rscratch1, [j_rarg0 + oopDesc::klass_offset_in_bytes()] # compressed klass
decode_heap_oop_not_null rscratch1, rscratch1
cmpq rax, rscratch1 # Inline cache check
jne SharedRuntime::_ic_miss_stub
nop # nops to align entry point
nop # 12 bytes pad for loops and calls
020 B1: # B6 B2 <- 1="" block="" font="" freq:="" head="" is="" junk="" nbsp="">
020 # stack bang
pushq rbp
subq rsp, #16 # Create frame
02c testl RCX, RCX
02e jle,s B6 P=0.001002 C=198529.000000
02e
030 B2: # B7 B3 <- 0.998998="" b1="" font="" nbsp="" req:="">
030 movl R11, RCX # spill
033 decl R11 # int
036 movl R8, RDX # spill
039 incl R8 # int
03c xorl R8, RDX # int
03f testl R11, R11
042 jle,s B7 P=0.001002 C=198529.000000
042
044 B3: # B5 B4 <- 0.997996="" b2="" font="" nbsp="" req:="">
044 movl R11, RCX # spill
047 addl R11, #-2 # int
04b movl RAX, R8 # spill
04e incl RAX # int
050 xorl RAX, R8 # int
053 testl R11, R11
056 jle,s B5 P=0.001002 C=198529.000000
056
058 B4: # B8 B5 <- 0.996996="" b3="" font="" nbsp="" req:="">
058 addl RCX, #-3 # int
05b movl RDX, RAX # spill
05d incl RDX # int
05f xorl RDX, RAX # int
061 nop # 2 bytes pad for loops and calls
063 call,static com.henryp.test.recursion.RecursionVsIterativeBenchmark::recursiveCall
# com.henryp.test.recursion.RecursionVsIterativeBenchmark::recursiveCall @ bci:17 L[0]=_ L[1]=_ L[2]=_
# com.henryp.test.recursion.RecursionVsIterativeBenchmark::recursiveCall @ bci:17 L[0]=_ L[1]=_ L[2]=_
# com.henryp.test.recursion.RecursionVsIterativeBenchmark::recursiveCall @ bci:17 L[0]=_ L[1]=_ L[2]=_
# OopMap{off=104}
068
068 B5: # N94 <- 0.99998="" b3="" b4="" b6="" b7="" font="" nbsp="" req:="">
068 addq rsp, 16 # Destroy frame
popq rbp
testl rax, [rip + #offset_to_poll_page] # Safepoint: poll for GC
073 ret
073
074 B6: # B5 <- 0.00100237="" b1="" font="" nbsp="" req:="">
074 movl RAX, RDX # spill
076 jmp,s B5
076
078 B7: # B5 <- 0.00100137="" b2="" font="" nbsp="" req:="">
078 movl RAX, R8 # spill
07b jmp,s B5
07b
07d B8: # N94 <- 9.96996e-06="" b4="" font="" nbsp="" req:="">
07d # exception oop is in rax; no code emitted
07d movq RSI, RAX # spill
080 addq rsp, 16 # Destroy frame
popq rbp
085 jmp rethrow_stub
085
What does all this mean?
Well, I am not an assembler guru but it seems to me that this code is being partially rolled into a more iterative style
Let's go through it. Ints count and countDown are initially stored in registers rdx and rcx respectively. We know this from:
#r016 rdx : parm 1: int
#r010 rcx : parm 2: int
B1
(Note the stack bang - that is, preparing the stack - at B1 every time we enter this method. That can cause overhead.)
Registers "%rsp and %rbp typically hold the stack pointer and base pointer, as their names imply." [1]. So these lines push the old base pointer on the stack and then the stack pointer points 16 memory addresses lower (stacks progress "towards lower memory addresses" [2]), reserving that memory for us.
020 # stack bang
pushq rbp
subq rsp, #16 # Create frame
Next we test to see if our second argument (countDown or RCX) is 0
02c testl RCX, RCX
and if so, we jump out of the method by jumping to B6 (which then jumps to B5 that removes the stack from and leaves this code).
02e jle,s B6 P=0.001002 C=198529.000000
B2
Assuming countDown wasn't 0, we continue. This is the more common path as Freq is almost 1.0 (that is, a certainty).
030 B2: # B7 B3 <- b1="" b="" nbsp="">Freq: 0.998998
030 movl R11, RCX # spillTake this iterative method:
int iterativeCall(int count, int maxCalls) {
for (int i = 0 ; i < maxCalls ; i++) {
count ^= count +1;
}
return count;
}
And this recursive method:
int recursiveCall(int count, int countDown) {
if (countDown <= 0)
return count;
count ^= count +1;
return recursiveCall(count, countDown - 1);
}
And compare the two. Using Caliper, the difference looks something like this:
To make recursive loops perform more like iterative loops, various tricks can be employed to make the compiled code loop over a block rather than jump recursively.
I noticed Hotspot do something similar to this. It's not fully optimized because it appears to reduce rather than avoid recursions.
This is how I did it. If we now add a static main method to our class containing the code above:
public static void main(String[] args) {
RecursionVsIterativeBenchmark app = new RecursionVsIterativeBenchmark();
for (int i = 0 ; i < 1000 ; i++) {
app.recursiveCall(0, 1000);
}
}
and run the code with:
/usr/java/jdk1.7.0.fastdebug/bin/java -XX:+UnlockDiagnosticVMOptions -XX:CompileCommand=print,com.henryp.test.recursion.RecursionVsIterativeBenchmark -server -XX:+PrintAssembly -XX:CompileThreshold=90000 -cp /home/henryp/workspace/myPerformance/target/classes/:/home/henryp/.m2/repository/com/google/caliper/caliper/0.5-rc1/caliper-0.5-rc1.jar:/home/henryp/.m2/repository/com/google/code/findbugs/jsr305/1.3.9/jsr305-1.3.9.jar:/home/henryp/.m2/repository/com/google/code/gson/gson/1.7.1/gson-1.7.1.jar:/home/henryp/.m2/repository/com/google/guava/guava/11.0.1/guava-11.0.1.jar:/home/henryp/.m2/repository/com/google/code/java-allocation-instrumenter/java-allocation-instrumenter/2.0/java-allocation-instrumenter-2.0.jar:/home/henryp/.m2/repository/asm/asm/3.3.1/asm-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-analysis/3.3.1/asm-analysis-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-commons/3.3.1/asm-commons-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-tree/3.3.1/asm-tree-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-util/3.3.1/asm-util-3.3.1.jar:/home/henryp/.m2/repository/asm/asm-xml/3.3.1/asm-xml-3.3.1.jar com.henryp.test.recursion.RecursionVsIterativeBenchmark
to make hotspot spit out the assembly code, we see:
{method}
- klass: {other class}
- this oop: 0x000000040d0e7970
- method holder: 'com/henryp/test/recursion/RecursionVsIterativeBenchmark'
- constants: 0x000000040d0e7078 constant pool [42] for 'com/henryp/test/recursion/RecursionVsIterativeBenchmark' cache=0x000000040d1372c0
- access: 0x81000000
- name: 'recursiveCall'
- signature: '(II)I'
- max stack: 4
- max locals: 3
- size of params: 3
- method size: 17
- vtable index: 21
- i2i entry: 0x00007f8d0501d960
- adapter: 0x00007f8d080b8f20
- compiled entry 0x00007f8d050dc877
- code size: 21
- code start: 0x000000040d0e7928
- code end (excl): 0x000000040d0e793d
- method data: 0x000000040d193b08
- checked ex length: 0
- linenumber start: 0x000000040d0e793d
- localvar length: 3
- localvar start: 0x000000040d0e794a
#
# int ( com/henryp/test/recursion/RecursionVsIterativeBenchmark:NotNull *, int, int )
#
#r018 rsi:rsi : parm 0: com/henryp/test/recursion/RecursionVsIterativeBenchmark:NotNull *
#r016 rdx : parm 1: int
#r010 rcx : parm 2: int
# -- Old rsp -- Framesize: 32 --
#r089 rsp+28: pad2, in_preserve
#r088 rsp+24: pad2, in_preserve
#r087 rsp+20: pad2, in_preserve
#r086 rsp+16: pad2, in_preserve
#r085 rsp+12: pad2, in_preserve
#r084 rsp+ 8: return address
#r083 rsp+ 4: Fixed slot 1
#r082 rsp+ 0: Fixed slot 0
#
000 N94: # B1 <- 1="" block="" font="" freq:="" head="" is="" junk="" nbsp="">
000 movl rscratch1, [j_rarg0 + oopDesc::klass_offset_in_bytes()] # compressed klass
decode_heap_oop_not_null rscratch1, rscratch1
cmpq rax, rscratch1 # Inline cache check
jne SharedRuntime::_ic_miss_stub
nop # nops to align entry point
nop # 12 bytes pad for loops and calls
020 B1: # B6 B2 <- 1="" block="" font="" freq:="" head="" is="" junk="" nbsp="">
020 # stack bang
pushq rbp
subq rsp, #16 # Create frame
02c testl RCX, RCX
02e jle,s B6 P=0.001002 C=198529.000000
02e
030 B2: # B7 B3 <- 0.998998="" b1="" font="" nbsp="" req:="">
030 movl R11, RCX # spill
033 decl R11 # int
036 movl R8, RDX # spill
039 incl R8 # int
03c xorl R8, RDX # int
03f testl R11, R11
042 jle,s B7 P=0.001002 C=198529.000000
042
044 B3: # B5 B4 <- 0.997996="" b2="" font="" nbsp="" req:="">
044 movl R11, RCX # spill
047 addl R11, #-2 # int
04b movl RAX, R8 # spill
04e incl RAX # int
050 xorl RAX, R8 # int
053 testl R11, R11
056 jle,s B5 P=0.001002 C=198529.000000
056
058 B4: # B8 B5 <- 0.996996="" b3="" font="" nbsp="" req:="">
058 addl RCX, #-3 # int
05b movl RDX, RAX # spill
05d incl RDX # int
05f xorl RDX, RAX # int
061 nop # 2 bytes pad for loops and calls
063 call,static com.henryp.test.recursion.RecursionVsIterativeBenchmark::recursiveCall
# com.henryp.test.recursion.RecursionVsIterativeBenchmark::recursiveCall @ bci:17 L[0]=_ L[1]=_ L[2]=_
# com.henryp.test.recursion.RecursionVsIterativeBenchmark::recursiveCall @ bci:17 L[0]=_ L[1]=_ L[2]=_
# com.henryp.test.recursion.RecursionVsIterativeBenchmark::recursiveCall @ bci:17 L[0]=_ L[1]=_ L[2]=_
# OopMap{off=104}
068
068 B5: # N94 <- 0.99998="" b3="" b4="" b6="" b7="" font="" nbsp="" req:="">
068 addq rsp, 16 # Destroy frame
popq rbp
testl rax, [rip + #offset_to_poll_page] # Safepoint: poll for GC
073 ret
073
074 B6: # B5 <- 0.00100237="" b1="" font="" nbsp="" req:="">
074 movl RAX, RDX # spill
076 jmp,s B5
076
078 B7: # B5 <- 0.00100137="" b2="" font="" nbsp="" req:="">
078 movl RAX, R8 # spill
07b jmp,s B5
07b
07d B8: # N94 <- 9.96996e-06="" b4="" font="" nbsp="" req:="">
07d # exception oop is in rax; no code emitted
07d movq RSI, RAX # spill
080 addq rsp, 16 # Destroy frame
popq rbp
085 jmp rethrow_stub
085
What does all this mean?
Well, I am not an assembler guru but it seems to me that this code is being partially rolled into a more iterative style
Let's go through it. Ints count and countDown are initially stored in registers rdx and rcx respectively. We know this from:
#r016 rdx : parm 1: int
#r010 rcx : parm 2: int
B1
(Note the stack bang - that is, preparing the stack - at B1 every time we enter this method. That can cause overhead.)
Registers "%rsp and %rbp typically hold the stack pointer and base pointer, as their names imply." [1]. So these lines push the old base pointer on the stack and then the stack pointer points 16 memory addresses lower (stacks progress "towards lower memory addresses" [2]), reserving that memory for us.
020 # stack bang
pushq rbp
subq rsp, #16 # Create frame
Next we test to see if our second argument (countDown or RCX) is 0
02c testl RCX, RCX
and if so, we jump out of the method by jumping to B6 (which then jumps to B5 that removes the stack from and leaves this code).
02e jle,s B6 P=0.001002 C=198529.000000
B2
Assuming countDown wasn't 0, we continue. This is the more common path as Freq is almost 1.0 (that is, a certainty).
030 B2: # B7 B3 <- b1="" b="" nbsp="">Freq: 0.998998
033 decl R11 # int
Here we put countDown into R11 (remember, RCX was our countDown value) and decrement this temporary store.
Next, we put our first argument, count, into a temporary store, R8. We increment this and XOR it with its old value.
036 movl R8, RDX # spill
039 incl R8 # int
03c xorl R8, RDX # int
And then we go back to countDown into R11 and check it's not 0, leaving the method if it is.
03f testl R11, R11
042 jle,s B7 P=0.001002 C=198529.000000
If it is, we've just benefited from a recursion optimization.
B3
But it generally continues. Inside the same block of code, we're going to decrease countDown by 2 and do the same thing again:
044 B3: # B5 B4 <- 0.997996="" b2="" font="" nbsp="" req:="">
044 movl R11, RCX # spill
047 addl R11, #-2 # int
Exactly the same adding of 1 and XORing of count is done again but this time time with temporary storage in register RAX.
04b movl RAX, R8 # spill
04e incl RAX # int
050 xorl RAX, R8 # int
And we again check countDown has not reached 0, ultimately dropping out of the routine if it has.
053 testl R11, R11
056 jle,s B5 P=0.001002 C=198529.000000
B4
I won't go into the details, but the same thing happens again. The original countDown is reduced by 3 this time and count is incremented and XORed with itself.
But this time, we do recurse with the values.
Finally
The rest of the paths end up at B5 through one path or another. (Note we poll for a garbage collection safepoint just before we leave the method. I spoke more about this here.)
Conclusion
Hotspot is making an attempt to partially tail optimize the code by making recursive code more iterative. Indeed, if the recursion was originally 2 deep, there would have been no recursion at all in the optimized code.
For all other recursions greater than 2, there is still a saving as there would be a recursion only every third calculation of count.
[1] Introduction to x64 Assembly, New York University
[2] Hacking Jon Erickson, p19.