So, continuing with squeezing more performance out of the back-end of our Java/Sybase app, I attached YourKit to the JVM and ran the soak tests for an hour or so.
One of our queries is a straight insert/update to two tables. Other than the tables also having triggers for further auditing purposes, there's nothing special here.
However, on inspection of where the time is being spent, I see half the time for this query is actually spent in handling the connection and the connection pool (we're using DBCP).
One of our queries is a straight insert/update to two tables. Other than the tables also having triggers for further auditing purposes, there's nothing special here.
However, on inspection of where the time is being spent, I see half the time for this query is actually spent in handling the connection and the connection pool (we're using DBCP).
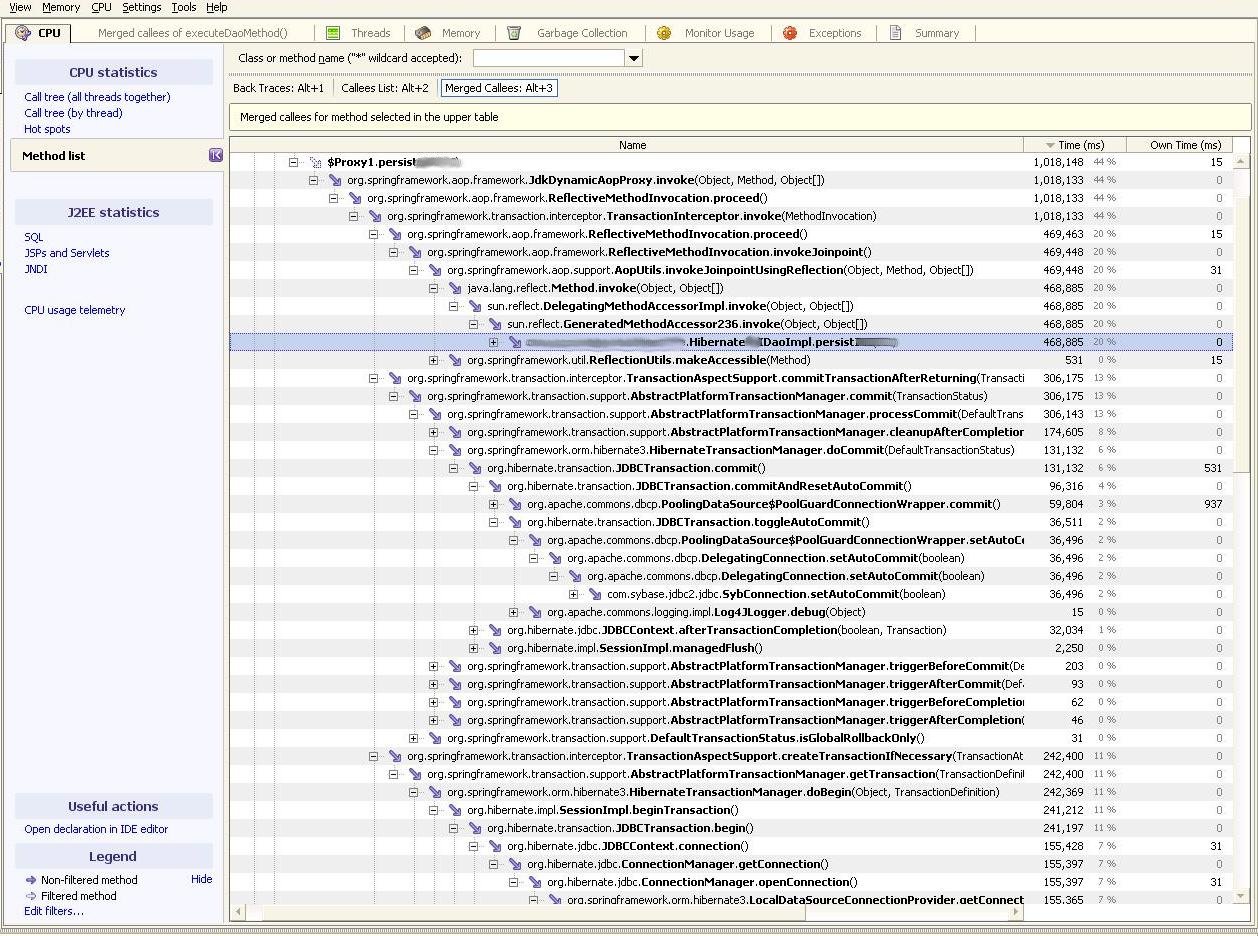
DBCP with Sybase JConnect 6 JDBC driver
Roughly 54% of the time of this innocuous call was spent doing something which was unrelated to my persistence request.
OK, so let's compare with Tomcat's connection pools. This should be faster as instead of our persistence thread wasting time with checking the status of the connection etc, another thread handles that for us (see ConnectionPool$PoolCleaner.run). And indeed so it proves to be:

Tomcat Connection Pool with Sybase JConnect 5.5 JDBC driver
Now, only 44% of time is spent getting and returning the connection back to the pool (and this is using an older JDBC driver - see below).
But still, there is more. Notice that a lot of time is spent in Hibernate's JDBCTransaction. This time is used checking the connection's auto-commit status and ensuring that it is set to true when returned to the pool.
This seems like an unnecessary overhead since with Sybase's JConnect 5.5, both of these actions are network calls (with JConnect 6, only setting the auto-commit flag is a network call. Reading it is not since the driver caches this information).
And althought the JDBC spec says "The default is for auto-commit mode to be enabled when the Connection object is created" (section 10.1.1), I can't find any reference that says this must also be true when storing the connections in a pool.
I see where the Hibernate team are going. They say "the intent is that the connection pool you use with Hibernate has autocommit *disabled*". But I can configure Tomcat's connection pool to always make this so. In which case, this extra checking and setting becomes an unnecessary overhead. It would be nice if JDBCTransaction could be configured such that when told explicitly that the pool it is using has auto-commit set to false, it does not make these calls...
Anyway, using Tomcat connection pool with all connections having auto-commit of false and using JConnect 6, the time to actually service my request went up to 85% of total time with only some 15% handling the pool, committing the transaction etc. Thus the median time to service this simple request dropped to about 70ms from about 200ms. Nice.
